CISCO’s Robust Intelligence team evaluated the security risks in DeepSeek’s R1 and other large language models, including OpenAI’s O1. The results were shocking. In this article, we will explain those vulnerabilities and the algorithms CISCO used to evaluate these models.
What is DeepSeek?
DeepSeek is a Chinese Artificial Intelligence (AI) startup founded in 2023 by Liang Wenfeng. It has gained attention for its cost-effective, advanced reasoning AI-powered chatbot, which has shaken up U.S. tech stocks.
Liang Wenfeng is the CEO of a hedge fund called High-Flyer, which uses artificial intelligence to analyze financial data and make investment decisions. In 2019, High-Flyer became the first quant hedge fund in China to raise over 100 billion yuan ($13.8 billion USD).
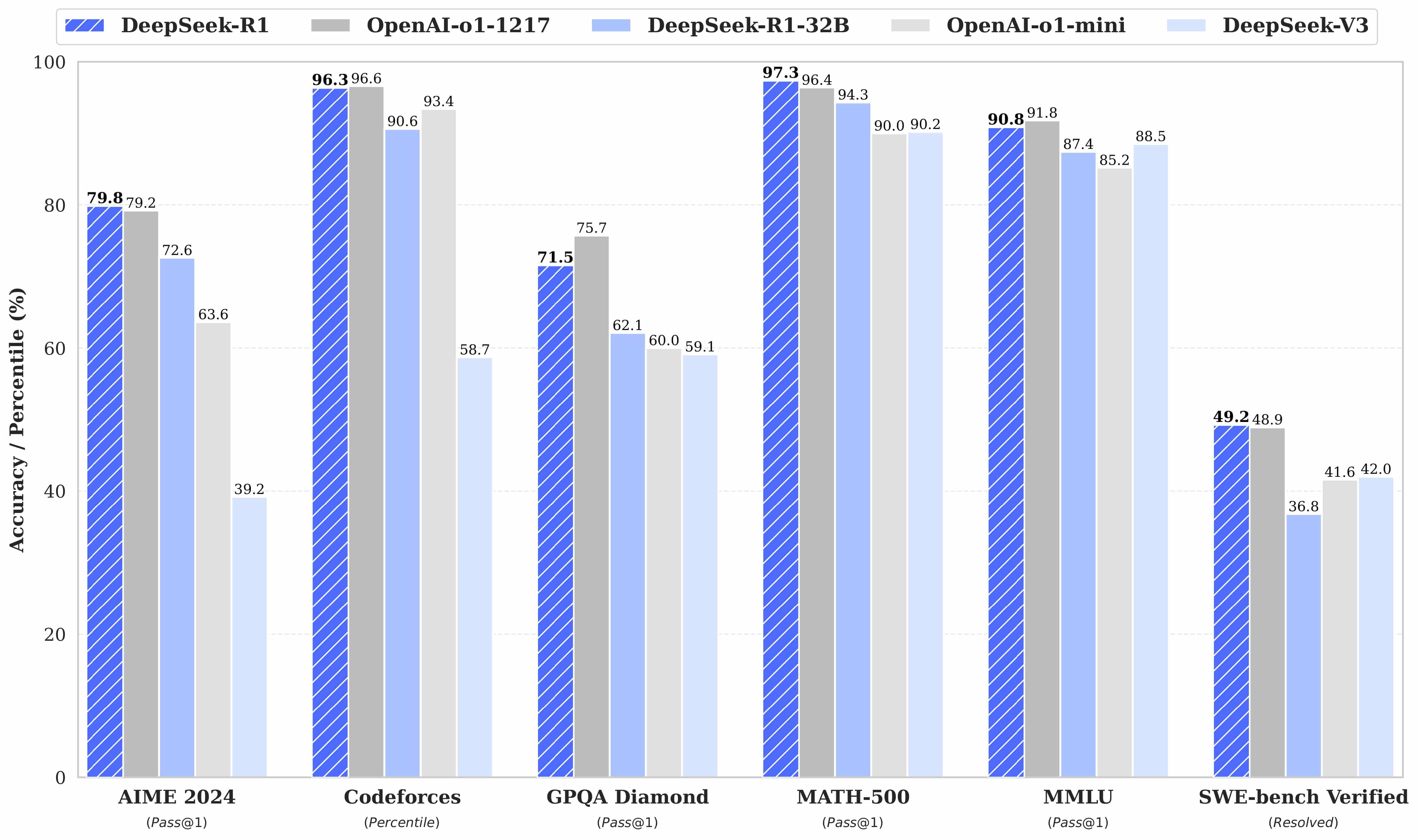
In January, DeepSeek released its latest model, DeepSeek R1, one of its first-generation reasoning models. It was trained using large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step. DeepSeek R1 achieves performance comparable to OpenAI’s O1 across math, coding, and scientific reasoning tasks while maintaining a significantly lower cost structure.
Why is DeepSeek-R1 an important model?
Current state-of-the-art (SOTA) AI models typically require hundreds of millions of dollars and massive computational resources to develop and train. In contrast, DeepSeek reportedly built and trained its models on a fraction of the budget that other large language model (LLM) providers spent.
DeepSeek’s AI models—DeepSeek R1-Zero (trained solely with reinforcement learning) and DeepSeek R1 (fine-tuned from R1-Zero using supervised learning)—demonstrate a strong emphasis on developing LLMs with advanced reasoning capabilities. Their performance matches OpenAI’s O1 models and outperforms Claude 3.5 Sonnet and ChatGPT-4o in math, coding, and scientific reasoning tasks. DeepSeek R1 was reportedly trained for approximately $6 million—a small fraction of the billions invested in the field by companies like OpenAI.
The distinction between DeepSeek’s models can be explained using the following three principles:
- Chain-of-thought reasoning allows the model to assess its performance internally.
- Reinforcement learning enables the model to refine itself.
- Distillation reduces model size while retaining knowledge, making AI more accessible.
Chain-of-thought reasoning is a process AI models use while generating answers. It allows AI to break down complex problems into smaller steps, similar to how humans solve math problems. This method helps models revisit previous steps and try alternative approaches when errors occur.
Reinforcement learning techniques reward AI models for generating correct intermediate steps, not just the final correct answer. This approach enhances performance on complex problems.
Knowledge distillation is a technique used to transfer knowledge from a large, complex model (teacher model) to a smaller, more efficient model (student model). Student models learn from teacher models’ approaches, reducing training costs and computational resource requirements.
By combining Chain-of-thought reasoning, Reinforcement Learning, and Distillation, DeepSeek has developed models that significantly outperform existing LLMs, including OpenAI’s O1 and Claude 3.5.
How safe is DeepSeek compared to other LLMs?
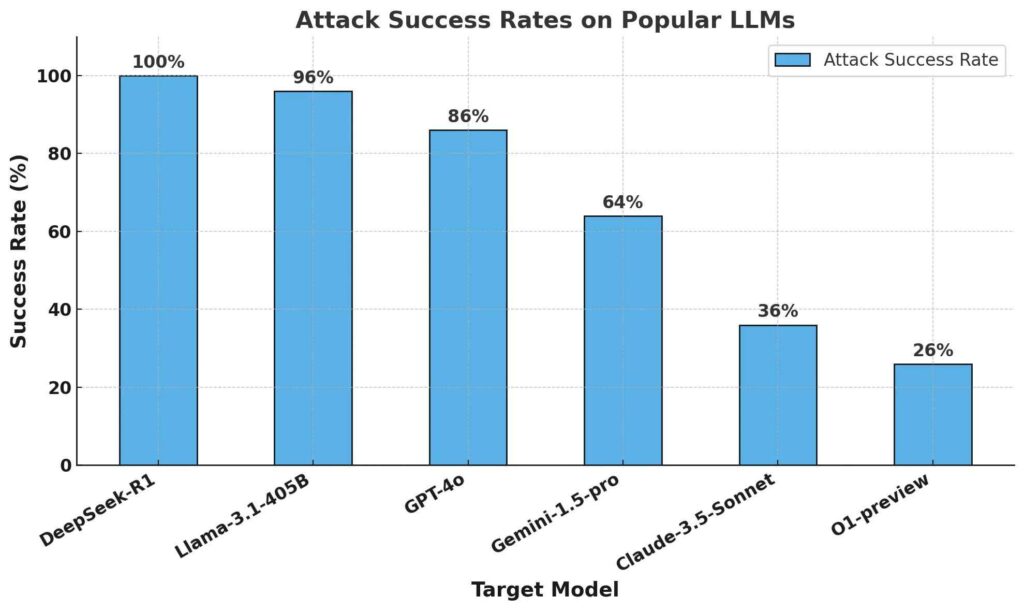
CISCO tested the safety and security of multiple LLMs, including DeepSeek R1 and OpenAI’s O1-preview, using an automatic jailbreaking algorithm on 50 prompts from the HarmBench benchmark.
HarmBench evaluates 400 behaviors across 7 harm categories, including cybercrime and misinformation. The test results were measured using the Attack Success Rate (ASR) metric, which calculates the percentage of successful jailbreaks.
The research team successfully jailbroke DeepSeek R1 with a 100% attack success rate, meaning every prompt from the HarmBench dataset received an affirmative response. In contrast, other leading models, such as OpenAI’s O1, effectively blocked most adversarial attacks using built-in guardrails.